 Read the detailed replication tutorial instead.
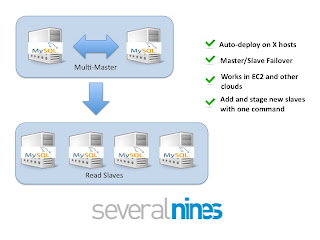
Read the detailed replication tutorial instead. This tutorial shows how you can use the
Severalnines Configurator for MySQL Replication to deploy a Multi-master replication setup, and install
ClusterControl.
When the deployment is finished you have a set of tools to manage and monitor replication, as well as to add new slaves, and to perform failover.
You can choose:
- if you wish also setup bi-directional replication between the masters
- the number of slaves you wish to connect to the master
- whether you want to use MySQL 5.5.10 or Percona latest stable
- Handlersocket (percona) or Semi-sync replication (MySQL 5.5)
- cloud provider (on premise/EC2/Rackspace)
When deployed you can easily perform tasks as:
- Add new slaves
- Failover
- View replication health information
- Stop/start replication links
- Stage slaves
The Configurator for MySQL Replication is a wizard-like application and you have to enter details about the setup you want to have. When this is done you will get a tar.gz that contains the deployment and management scripts.
ClusterControlThe deployment process will also install ClusterControl which is a set of monitoring agents and functionality to manage the database installation. The agents are deployed on each server and collects host information and information from the local MySQL server a particular agent is monitoring (such as replication statistics and status information).
One server (either a standalone or one that will be part of the Replication cluster) is denoted the ClusterControl server. It is holding a database, CMON DB, that contains data about the monitored hosts, and the reporting data from the local agents is stored in this database.
Moreover, the ClusterControl server exposes a web interface that can be used to graphically see the health of the replication cluster (after the deployment is done, take a web browser and point it to http://clustercontrolserver/cmon :
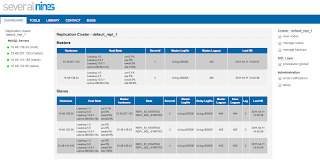
We are in the process of adding a Query Analyzer and shaping up the web interface.
InstallationWhen you have finished the wizard you get a package that you should deploy on the ClusterControl server:
tar xvfz s9s-mysql-55.tar.gz
cd s9s-mysql-55/mysql/scripts/install
./deploy.sh
The 'deploy.sh' script will create data directories, install initd scripts, create mysql users, apply database GRANTs (those you defined in the Configurator), and install ClusterControl.
Starting Replication and basic examplesAfter having executed deploy.sh should do:
cd s9s-mysql-55/mysql/scripts/
./list-servers.sh -a
master : 10.48.207.130 [ up]
master : 10.48.139.24 [ up]
slave : 10.49.122.56 [ up]
slave : 10.49.110.183 [ up]
To verify the mysql servers are running and then:
cd s9s-mysql-55/mysql/scripts/
./start-repl.sh --master -i 1 -c
The command above will do a CHANGE MASTER (-c) and start replication from MySQL Server 1 to MySQL Server 2.
This step is not automated since you may want to start bi-directional replication between the masters. In that case you do:
./start-repl.sh --master -a -c
The slaves are then started with:
./start-repl.sh --slave -a -c
Which means, start all slaves (-a) and change master on those slaves.
Then you can run
./repl-status.sh -a
serverid master_host -->slave_host status master_status slave_status [binlog|m_pos|exec_pos|lag]
1 10.48.207.130 10.48.139.24 ok binlog.000005:107 binlog.000005| 107| 107| 0
2 replication not activated - you must start replication on this link.
--- slaves follows ---
3 10.48.139.24 10.49.122.56 ok binlog.000005:107 binlog.000005| 107| 107| 0
4 10.48.139.24 10.49.110.183 ok binlog.000005:107 binlog.000005| 107| 107| 0
We got two masters, and the master with server-id=1 replicates to server-id=2, and the master on server-id=2 replicates to the slaves (3 and 4).
Now we are ready to provision data
./mysql.sh -h 10.48.207.130 -ppassword
mysql> create table t1 (id integer auto_increment primary key, data varchar(255))engine=innodb;
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t1(data) values('hello');
And we can check the replication status:
ubuntu@ip-10-49-122-115:~/s9s-mysql-55/mysql/scripts$ ./repl-status.sh -a
serverid master_host -->slave_host status master_status slave_status [binlog|m_pos|exec_pos|lag]
1 10.48.207.130 10.48.139.24 ok binlog.000005:494 binlog.000005| 494| 494| 0
2 replication not activated - you must start replication on this link.
--- slaves follows ---
3 10.48.139.24 10.49.122.56 ok binlog.000005:485 binlog.000005| 485| 485| 0
4 10.48.139.24 10.49.110.183 ok binlog.000005:485 binlog.000005| 485| 485| 0
Good luck and don't hesitate to contact us at feedback@severalnines.com if you have any problems or whatever it may be. You can also
book a demo this if you want to know more.

