There are various setups and solutions to solve the problem of having redundant mysql masters and scaling writes on them. MySQL Cluster can be an alternative. Here is why and how:
Pros:
- No need to worry about DRBD failover and recovery times
- No need to worry about potential data loss when failover from active master to standby master (has all binlog really been replicated over from the failed master?)
- Writes go to any mysql server connected to the Cluster - thus writes are easy to scale
The data nodes will then send the committed writes to every mysql server with --log-bin enabled.
- MySQL Cluster can handle a lot of writes (but the slaves can become the bottleneck)
- Data nodes can be added online (MySQL Cluster 7.0) - thus write scaling is easy and can be done on-demand
- Add new, consistent, slaves online (thanks to the online backup in MySQL Cluster)
- Simple and very fast master failover policy - all masters connected to the cluster will receive the same events, thus (when both are working) they will have the same content in the binary log - none is lagging behind.
- No additional hardware compared to a normal HA setup of the masters (two computers are enough)
Worried that NDB stores data in RAM - well
use disk based tables!
Setting up MySQL ClusterYou need to have at least:
- 2 computers (HA with dual switches, nics and bonding, split brain only if both links are broken)
- dual switches, dual nics (bonded).
- each computer runs:
1 data node (ndbd/ndbmtd),
1 mysql server (master),
1 ndb_mgmd
or - 4 computers (better HA and no risk for network partitioning/split brain)
- dual switches, dual nics (bonded).
- two computers each runs:
1 data node (ndbd/ndbmtd),
- two computers each runs:
1 mysql server (master), 1 ndb_mgmd.
Then it is of course possible to have more data nodes, more mysql servers etc, but we recommend two mysql servers that are masters in the replication so it is possible to failover between them.
With
www.severalnines.com/config you can easily generate either of these setups, and have a running Cluster in a couple of minutes.
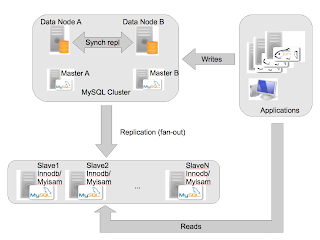
The idea here (just as in a normal HA MySQL setup) is to have two masters,
master_a and
master_b. The slaves will replicate from
master_a and failover to
master_b if
master_a fails!
Note that you can write to _all_ mysql servers, and the data nodes will send the changes to the mysql servers that has --log-bin enabled.
Preparation of SlavesYou must chose between 1) and 2) below, else the replication won't work:
1. Enable INDEMPOTENCY in my.cnf of the slaves using slave-exec-mode:
--slave-exec-mode=IDEMPOTENT
2. if you want to use STRICT (default), then you have to set on the master mysql servers (my.cnf):
--ndb-log-update-as-write=O
Meaning that updates will be logged as updates, and not as writes.This downside with this is that twice as much as data will be sent (there is a before image and an after image for each update).
Each slave must have the table
mysql.ndb_apply_status:
mysql_slave> use mysql;
mysql_slave> CREATE TABLE `ndb_apply_status` (
`server_id` int(10) unsigned NOT NULL,
`epoch` bigint(20) unsigned NOT NULL,
`log_name` varchar(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`start_pos` bigint(20) unsigned NOT NULL,
`end_pos` bigint(20) unsigned NOT NULL,
PRIMARY KEY (`server_id`) USING HASH)
ENGINE=INNODB DEFAULT CHARSET=latin1;
This table is used to know what data has been applied on the slave and from which master (see below more a longer explanation).
Preparation of Masters (masterA, masterB)Ensure you have the following in the my.cnf of the master mysql servers::
[mysqld]
...
#if you didnt set --slave-exec-mode=IDEMPOTENT on the slaves you must set:
ndb-log-update-as-write=O
#else
ndb-log-update-as-write=1
#endif -- so pick one of the above!!
#enable cluster storage engine:
ndbcluster
#connect to cluster:
ndb-connectstring=<hostname of ndb_mgmd:port>
#sync after each epoch (10 ms of transactions) - here is a disk tuning possibility.
sync-binlog=1
#you may also want to set binlog_cache_size (if Binlog_cache_disk_use is growing):
binlog_cache_size=1048576
GRANT the replication user, e.g,
mysql>GRANT REPLICATION SLAVE ON *.* TO repl@'%' IDENTIFIED BY 'password'
Creating the tablesOn MySQL Cluster
Create all the tables for the application(s) using
engine=NDBCLUSTER.
On each slave
Create all the tables for the application(s) using e.g
engine=MYISAM or
engine=INNODB.
Staging a slave - with traffic on Cluster:In order to get a consistent slave you have to do as follows:
Backup the ClusterUsing the management client:
ndb_mgm>start backup
Copy all the backup files to the same location.
If you use the
Configurator scripts:
./start-backup.sh /path/mycentral_backupdir/
all backup files will be copied from the nodes to
/path/mycentral_backupdir/Remember the
stopGCP=<some number> that is printed at the end of the backup.
If you use
ndb_mgm -e "start backup" then it will look like this:
ndb_mgm -e "start backup"
Connected to Management Server at: localhost:1186
Waiting for completed, this may take several minutes
Node 3: Backup 14 started from node 1
Node 3: Backup 14 started from node 1 completed
StartGCP: 98278 StopGCP: 98281
#Records: 2058 #LogRecords: 0
Data: 51628 bytes Log: 0 bytes
If you use
./start-backup /tmp then it will look like this:
Backup has completed on data nodes.
Copying backup files to /tmp//BACKUP-2009May09-150743
BACKUP-15.3.log 100% 52 0.1KB/s 00:00
BACKUP-15-0.3.Data 100% 26KB 26.1KB/s 00:00
BACKUP-15.3.ctl 100% 11KB 10.6KB/s 00:00
BACKUP-15.4.log 100% 52 0.1KB/s 00:00
BACKUP-15-0.4.Data 100% 26KB 25.7KB/s 00:00
BACKUP-15.4.ctl 100% 11KB 10.6KB/s 00:00
Backup completed and backup files can be found in /tmp//BACKUP-2009May09-150743
Use the StopGCP to setup Cluster to non-cluster replication:
StopGCP: 98482
This is important as this tells where the backup ended, and from what point the slave should get the changes. This number will be used later when the replication is setup.
Convert Cluster backup data files to CSV filesFor each backup file (for each data node in the master cluster) run:
ndb_restore -c <connectstring>
-b <backupid>
-n <nodeid>
--print-data
--print-log
--append
--tab=<output directory>
--fields-enclosed-by="'"
--fields-separated-by=","
--lines-terminated-by="\n"
or if you are using the
Configurator scripts:
./restore-backup.sh --csv --backupdir=/path/mycentral_backupdir/ --csvdir=/mycsv/
This will create one txt file for each table and put it in
--csvdir (Configurator) or
--tab=<outputdir> for the vanilla ndb_restore.
It will also tell you (if you used start-backup.sh) the stop gcp:
./restore-backup.sh --csv
--backupdir=/cluster/backups/BACKUP-2009May10-165004
--csvdir=/cluster/backups/csv
...
To setup replication use StopGCP: 1511
Data is appended to the txt files, so running the command more than once is bad. Better delete the old txt files first.
Loading the .txt (CSV) into Slave
For all tables:
mysql_slave> LOAD DATA INFILE 'tablename.TXT'
INTO table <tablename>
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
LINES TERMINATED BY '\n';
Now the slave is at the same state as the when the backup finished in the Cluster.
Staging a slave - no traffic on Cluster:You can use mysqldump for this.
host> mysqldump -u<user> -p<password> <database> > database_dump.sql
Then you copy the database_dump.sql and change the
engine=ndb to
engine=innodbhost> sed -i -e 's#ndbcluster#innodb# database_dump.sql
Then you have to find the good starting position from
master_a:
master_a> show master status;
Remember the binlog filename and position, you will need it in the next step.
Starting the replicationCreate and grant the replication user (not shown here)
If you have staged the slave using
mysqldump, then you go directly to
CHANGE MASTER.. using the BINLOG and POS from the previous step.
Find out where the slave should start replicating from using the
stopGCP from the previous step "Backup the Cluster".
mysql_masterA> SELECT @file:=SUBSTRING_INDEX(File, '/',-1),
@pos:=Position
FROM mysql.ndb_binlog_index
WHERE gci>@stopGCP ORDER BY gci ASC LIMIT 1;
if the query returns nothing (this means that no changes has happened on the cluster after the backup was completed) run:
mysql_masterA> SHOW MASTER STATUS;
Then change master
mysql_slave> CHANGE MASTER TO MASTER_HOST='masterA',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='@file',
MASTER_LOG_POS=@pos;
mysql_slave> START SLAVE IO_THREAD;
## verify slave connected to masterA:
mysql_slave> SHOW SLAVE STATUS\g
if above is ok:
mysql_slave> START SLAVE SQL_THREAD;
mysql_slave> SHOW SLAVE STATUS\g;
Master FailoverFailover from masterA to masterB
mysql_slave> STOP SLAVE;
mysql_slave> SELECT @epoch:=max(epoch) FROM mysql.ndb_apply_status;
mysql_masterB> SELECT @file:=SUBSTRING_INDEX(File, '/', -1),
@pos:=Position
FROM mysql.ndb_binlog_index
WHERE epoch>@epoch ORDER BY epoch ASC LIMIT 1;
If the query returns nothing (meaning nothing has been written to the master since the failure of masterA) do:
mysql_masterB> SHOW MASTER STATUS;
#use the position and file in the query below:
Then change master
mysql_slave> CHANGE MASTER TO MASTER_HOST='masterA',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='@file',
MASTER_LOG_POS=@pos;
mysql_slave> START SLAVE:
Master crashesWhen the master restarts after a crash, it will write a
LOST_EVENTS event into its binary log.
If a
LOST_EVENTS event is received on a slave, the slave will stop, and you have to do a Master Failover.
Master connection glitch between data node and a master mysql serverIf the master would lose contact for a very short period of time with the cluster, then a
LOST_EVENTS event will be written into the binary log. See above.
ndb_apply_status, epochs and ndb_binlog_indexThe
mysql.ndb_apply_status is very important as it stores what epochs from the Cluster that the slave has applied.
The epochs are consistent units and stores 10ms (controlled by
TimeBetweenEpochs in config.ini) of committed transactions.
On the master side, the epochs are mapped to binary log filename and position in the
mysql.ndb_binlog_index table.
The
mysql.ndb_binlog_index table is a
MYISAM table is local to each master and is the glue between what epoch has been applied on the slave, and what binary log and position it corresponds to for the master.
MonitoringReplication - you can use Enterprise Monitor or whatever monitoring tool you prefer to monitor the replication and the mysql servers. Scripts for automatic failover must be implemented.
Cluster - you can use
cmon to monitor the data nodes and the other components connected to the Cluster. The web interface will soon look better :)
Possible ExtensionsYou can of course give the master mysql servers one virtual IP and use Hearbeat to failover the IP. This simplifies for the applications.
Bugs and Issues - TIMESTAMP
Be careful with TIMESTAMP. Currently the ndb_restore program does not generate the timestamp using the MySQL TIMESTAMP, but rather it is a UNIX_TIMESTAMP.
I have written a
bug report on this. In the meantime, you have to convert the TIMESTAMP columns in the .txt files to the MySQL TIMESTAMP format YYYY-MM-DD HH:MM:SS.
Please note that this is not a problem if you use
mysqldumpI will update this part if you find any other problems - just let me know.
Thanks to Magnus Blåudd, Cluster Team, for your input on this post!



