In this blog, we will see what a good MySQL Cluster setup looks like.
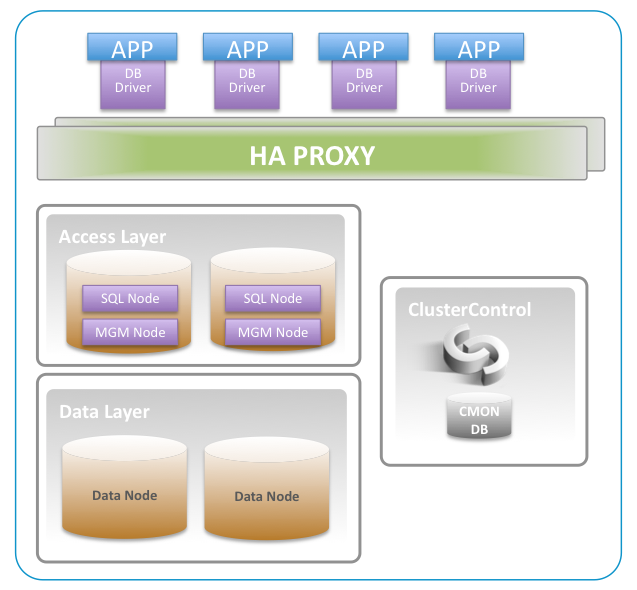
MGM Node - holds the configuration for MySQL Cluster in a file called config.ini. It also writes a cluster log, and takes part in arbitration to prevent split-brain or network partitioning.
You are recommended to have two MGM Nodes for redundancy. Since MGM hardly use any resources, and is not involved in query processing or routing of requests, it can be colocated with the SQL Nodes/Access Nodes.
Data Node - stores the data and the tables. Tables are divided up into partittions, and the number of partitions depends on the number of data nodes (and the number of Local Query Handlers). Data distribution is automatic and by default is based on the hash of the primary key to conclude which partition a particular data item should be written. You can also partition the data on part of the Primary Key (using PARTITION BY KEY(part_of_pk) if you want to group e.g users together with its associated data.
The data nodes takes cares of managing the transactions, recovery, etc etc. Failover is automatic, but the application is responsible for retrying failed transactions. Data can either be written in in-memory tables (fastest) or on disk tables (slower).
For redundancy you need at least two data nodes. Data nodes usually operate in pairs, so the number of data nodes would be two, four, six, etc. The data nodes should have many cores, fast cores, enough RAM to store your data, and fast disks (SAS 10-15KRPM and/or SSD for disk data tables). On EC2, IOPS instances are prefered.
Since the Linear two-phase commit protocol is used to write data onto two partitions (synchronous replication between data nodes) it is recommended to have as fast network as possible, 1 Gig-E, 10Gig-E, Infiniband or even Dolphin ICS IX PCI Express adapters.
Distributing Data Nodes that belong to one cluster over WAN is generally not recommended, unless the WAN connection is very stable and the latency is very low (at most a few milliseconds).
SQL Node / Access Node - the most common way to read/write data to the Data Nodes is by using the MySQL Server (aka SQL Node). A query comes into the SQL Node. The SQL Node parses, optimizes and executes the query on the Data Nodes. Other ways of connecting to the Data Nodes includes Cluster/J (Java driver), Memcached, or directly from the NDBAPI (C++) api. All methods mentioned above accessing the Data Nodes boil down to the NDBAPI requests being sent across the wire.
You need at least two SQL Nodes for redundancy. Nodes in the access layer should have fast CPUs, disks are not important, fast network to the data nodes (same specs as for the data nodes), and about 2+ GB of RAM (depending on the number of connections, per thread buffers etc). Do not co-locate the SQL Nodes/Access Nodes with the Data Nodes.
SQL Load Balancing with HAProxy - HAProxy is a load balancer, and load balances application requests to multiple SQL Nodes. We recommend 2 instances of HAProxy for redundancy. HAProxy has neat features like queuing and throttling of connections towards one or more SQL Nodes, which is great for overload control. Unless you have 10 or more app servers, we recommend to deploy the HAProxy servers directly on the machine running the app servers.
ClusterControl - This is a management server that gives a single, consolidated view of all the nodes in the cluster. It collects status information from all the nodes, and reacts on this information to provide automatic recovery, scaling/add nodes, health reports, query monitoring, notifications, and backup. Requires approx 2 CPU cores, 16Gb of disk space, and at least 1GB of RAM.
We recommend that you do not co-locate the ClusterControl server with any node that is part of the MySQL Cluster setup.
Putting it all together:
Bare metal or Virtualized platform?
Generally, you can run MySQL Cluster on virtualized hardware if you keep attention to:
- Latency
- Disk speed
The Data Nodes are the ones that are most sensitive. Cloud servers work fine as well. As an example, Paypal deploys a number of MySQL Clusters on Amazon. They use small AWS instances for their MGM and SQL nodes, but XL instances for Data Nodes.
If you e.g use VMWare, then you want to have:
- nodes in one node group running on separate instances, and those instances should be on different physical hosts. Else if the host goes down, the entire node group will go down, and then the entire cluster
- the physical host running as few instances as possible
- as less sharing of possible of the physical hosts resources (like CPU and disk) - you don't want two data nodes share the same physical core e.g.
2 comments:
Hi, did you try the galera load balancer ? (http://www.codership.com/products/galera-load-balancer).
I want to test this configuration, but still don't know wjere to install the load balancer in my situation.
Cheers
HI,
I havent tried it but I guess you could replace HaProxy with GLB. Let me know what happens!
Best regards,
Johan
Post a Comment