FOREIGN KEYs in MySQL Cluster is a big step forward. It is now possible to run enterprise software with NDB Cluster as the storage backend. Over the years, the lack of FOREIGN KEYs have been one of the most limiting pieces of functionality. Who wants to fiddle with TRIGGERs or recode applications to enforce data integrity?
But finally, it is here. It is implemented natively at the Data Node level, where NDB stores its data. It is well known that FOREIGN KEYs come with an overhead. E.g., when writing a record into a child table, the existence must be checked in the parent table. Since data is distributed across multiple Data Nodes, the child record and parent record may be on different nodes or shards (Node Groups). Hence there is extra work to be done in terms of internal triggers and network communication, the latter being the more costly. The performance impact must be taken into account when doing capacity planning of the cluster.
The question is how much the impact is, and that is what we will look at next.
We will do a simple test to get some initial numbers; insert random records into a table containing FOREIGN KEY constraints, and repeat the test on a table without the constraints. We created the following tables:
create table users_posts_fk (uid integer ,fid integer ,pid integer auto_increment,message varchar(1024),primary key(uid,fid, pid),constraint fk_forum foreign key(fid) references forum(fid) on delete cascade,constraint fk_user foreign key(uid) references users(uid) on delete cascade) engine=ndb;
The table above references to two tables, forum (on the key fid), and users (on the key uid). To insert a record in users_posts_fk requires that the user and forum exists in the parent tables. The users_posts table below does not have any foreign key constraints:
create table users_posts (uid integer ,fid integer ,pid integer auto_increment,message varchar(1024),primary key(uid,fid, pid),key forum(fid)) engine=ndb;
The parent tables (referenced by users_posts_fk) looks like:
create table users(uid integer auto_increment primary key,name varchar(255),email varchar(255),view_cnt bigint unsigned default 0,created bigint unsigned default 0) engine=ndb;create table forum(fid integer auto_increment primary key,name varchar(255)) engine=ndb;
- two data nodes (4 cores, 4GB RAM)
- two mysql servers (4 cores, 2GB RAM)
- Severalnines bencher co-located with one mysql server
It is not a powerful setup at all and not intended to break any benchmark records, but it is good enough for our comparison.
Bencher was used to drive load and to insert random records the users_posts/users_posts_fk table. Each record inserted had a record size of 168 bytes, and bencher was started with 8 threads, each inserting 125 000 records for a total of 1M records:
./bencher -ucmon -pcmon -h127.0.0.1 -t8 -l125000
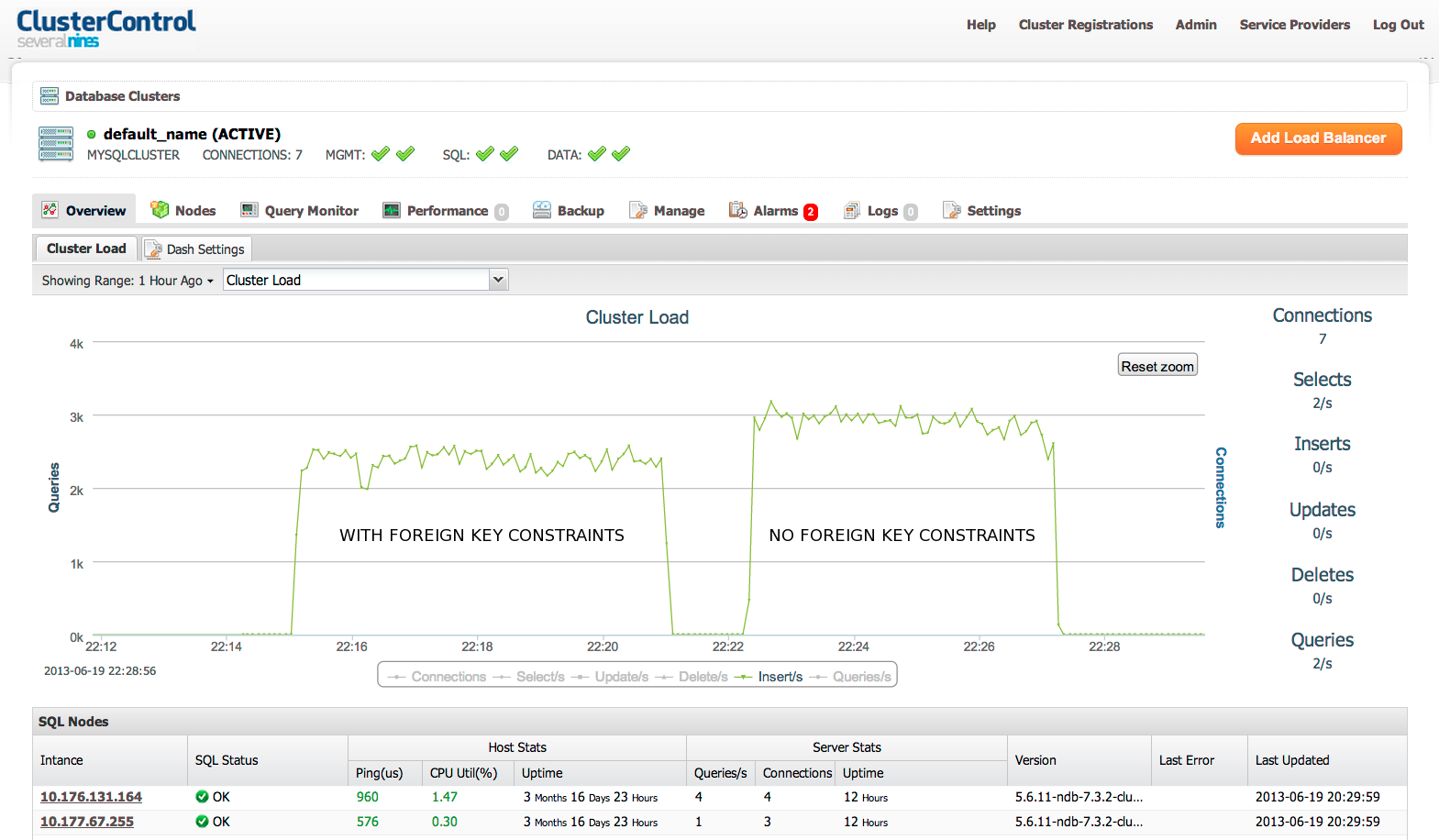
Results
No FOREIGN KEY constraints:
Summar (No FK)y:
--------------------------
Average Throughput = 2793.55 tps (stdev=52.96)
95th Percentile Latency (us)=3712.00
With two FOREIGN KEY constraints:
Summary (Two FKs):
--------------------------
Average Throughput = 2289.81 tps (stdev=52.39)
95th Percentile Latency (us)=4689.00
So, with two FOREIGN KEYs, we saw an 18% performance penalty.
Wtih one FOREIGN KEY constraint:
What if we have only one FOREIGN KEY in the table? For the next result the fk_forum is dropped:
alter table users_posts_fk drop foreign key fk_forum;
Summary (One FK)
--------------------------
Average Throughput = 2280.83 tps (stdev=58.84)
95th Percentile Latency (us)=4867.00
There is hardly no difference in performance when having one or two foreign keys in the table. This is mainly because NDB Cluster makes a fantastic job at batching requests so sending one or two requests in a tcp packet does not make any difference and executing the foreign key check on the target node is very cheap compared to the network cost.
Well done MySQL Cluster Team, you guys rock!
1 comment:
Of note, unlike InnoDB you can still use foreign keys in NDB when you have user defined partitioning. This user defined partitioning may be used to ensure that related rows exists on the same node (ldm) potentially further minimizing the overhead.
Post a Comment